iNaturalist Datasource to MS Fabric Data Lakehouse
Initially, I used Power BI to analyze iNaturalist data in Power BI by directly connecting to the API data source and performing JSON transoformations of the api response in Power Query (see Related Content). This was a good way to prototype analysis and visualization of iNaturalist data. Now I want to incorporate this data into a Fabric / Synapse data lakehouse saving the data as raw JSON files, transforming to delta tables and then loading to a SQL star schema data mart. This follows the Onelake Medallion Lakehouse Architecture.
Lakehouse Data Storage (OneLake) The following Fabric resources were created following the above architecture guideline.
- ADFS Gen 2 file folder for raw JSON files (Bronze Medalion Level)
- Delta tables for tabular data from JSON transformations (Sliver Medalion Level)
- SQL analytical data mart with star schema and conformed dimensions (Gold Gold Medalion Level)
Synapse Pipeline
Web Activity to get results per page and total resultsFor Each Container
- Calculate pages to iterate
- Copy Data - API Response JSON to Data Lake folder
- Save data to Lakehouse file storage, appending page number to the destination file name.
PySpark Notebook- Read data from Lakehouse file storage
- Transform JSON in dataframe
- Write dataframe to Delta table
Copy Data – Delta table to SQL Landing table- Configure Endpoints
- Map Columns
Execute Stored Procedures for incremental load to SQL Dimension and Fact tables
Here is the resulting pipeline:
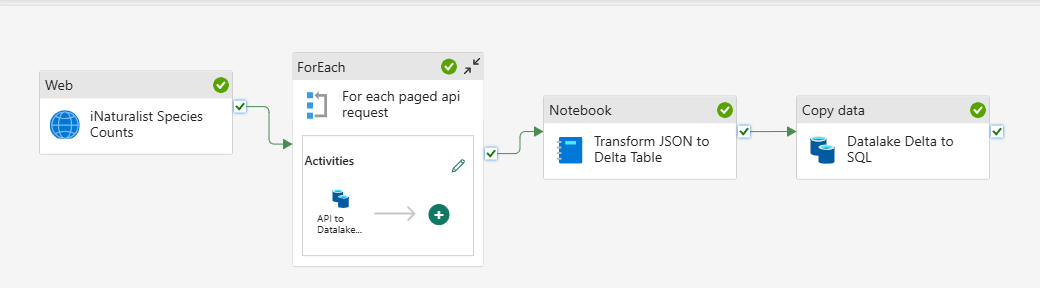
Notes:
- While some api paging features are built into the copy data activities the iNaturalist API implementation paging required dynamically setting the url in a for each loop. This requires some string concatenation to build the url with the correct query parameter string for each api request.
Related Content
iNaturalist APIs
iNaturalist Observations - Power BI
iNaturalist Observations - Power BI
Copy Data Pagination Support
Datalake, Fabric, Lakehouse Architecture, iNaturalist — Nov 14, 2024